 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the ethics of constructing conscious AI
Mar 13, 2023In its pragmatic turn, the new discipline of AI ethics came to be dominated by humanity's collective fear of its creatures, as reflected in an extensive and perennially popular literary tradition. Dr. Frankenstein's monster in the novel by Mary Shelley rising against its creator; the unorthodox golem in H. Leivick's 1920 play going on a rampage; the rebellious robots of Karel \v{C}apek -- these and hundreds of other examples of the genre are the background against which the preoccupation of AI ethics with preventing robots from behaving badly towards people is best understood. In each of these three fictional cases (as well as in many others), the miserable artificial creature -- mercilessly exploited, or cornered by a murderous mob, and driven to violence in self-defense -- has its author's sympathy. In real life, with very few exceptions, things are different: theorists working on the ethics of AI completely ignore the possibility of robots needing protection from their creators. The present book chapter takes up this, less commonly considered, ethical angle of AI.
Verbal behavior without syntactic structures: beyond Skinner and Chomsky
Mar 11, 2023What does it mean to know language? Since the Chomskian revolution, one popular answer to this question has been: to possess a generative grammar that exclusively licenses certain syntactic structures. Decades later, not even an approximation to such a grammar, for any language, has been formulated; the idea that grammar is universal and innately specified has proved barren; and attempts to show how it could be learned from experience invariably come up short. To move on from this impasse, we must rediscover the extent to which language is like any other human behavior: dynamic, social, multimodal, patterned, and purposive, its purpose being to promote desirable actions (or thoughts) in others and self. Recent psychological, computational, neurobiological, and evolutionary insights into the shaping and structure of behavior may then point us toward a new, viable account of language.
Learning similarity-based word sense disambiguation from sparse data
Jul 11, 1996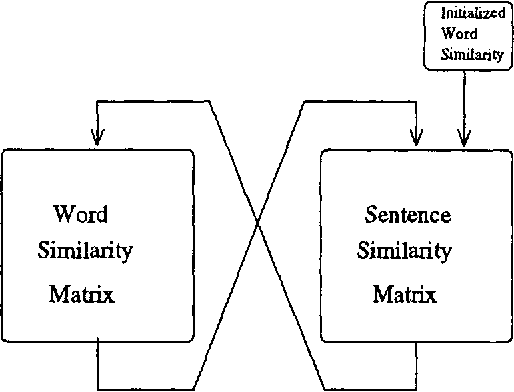
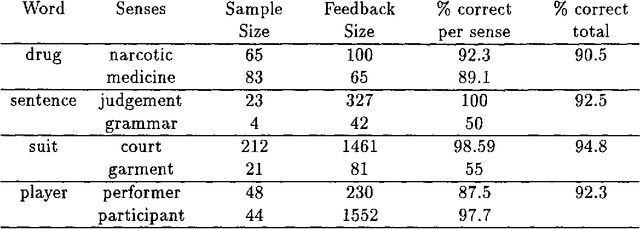
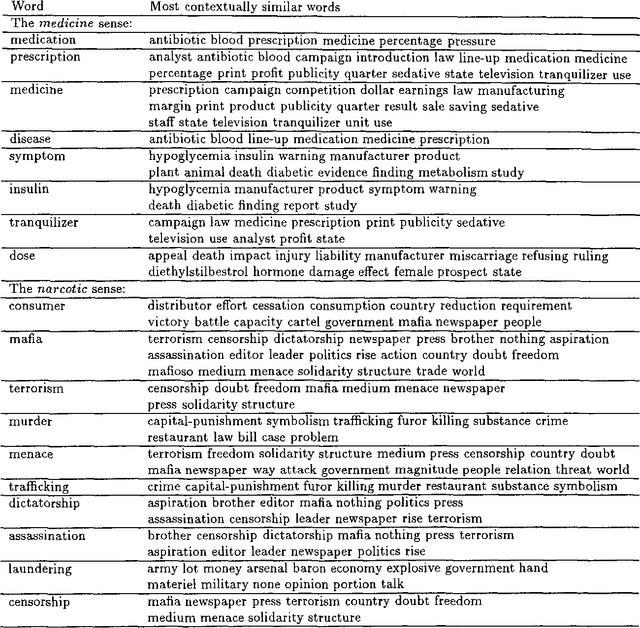
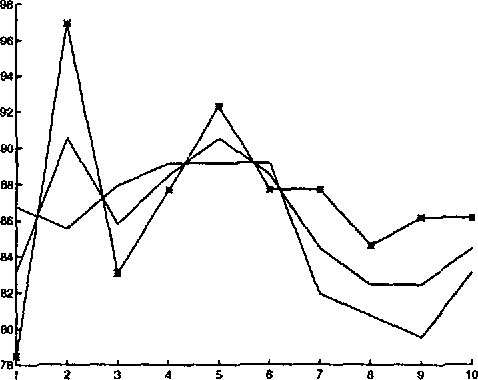
We describe a method for automatic word sense disambiguation using a text corpus and a machine-readable dictionary (MRD). The method is based on word similarity and context similarity measures. Words are considered similar if they appear in similar contexts; contexts are similar if they contain similar words. The circularity of this definition is resolved by an iterative, converging process, in which the system learns from the corpus a set of typical usages for each of the senses of the polysemous word listed in the MRD. A new instance of a polysemous word is assigned the sense associated with the typical usage most similar to its context. Experiments show that this method performs well, and can learn even from very sparse training data.